State of the Art,
Verified
Independent ML benchmarks across 17 research areas. Track progress, find implementations, compare models.
Vision, NLP, reasoning, code, speech, medical, robotics, and more. All results verified with source links.
The Ralph Loop: AGI's Dumbest Secret
What if the secret to AGI is while(true)? Interactive visualizations of Wolfram Rule 30, OODA loops, and the $50K→$297 technique.
Explore Research Areas
17 domains. 286+ benchmarks. Find SOTA for your task.
Computer Vision
Detection, segmentation, classification, OCR
10 tasksNLP
Language models, QA, translation, NER
9 tasksReasoning
Mathematical, logical, commonsense
MATH, GSM8KCode
Generation, SWE-bench, debugging
6 tasksSpeech
ASR, TTS, speaker verification
5 tasksMedical
Imaging, diagnosis, clinical NLP
4 tasksMultimodal
Vision-language, VQA, text-to-image
5 tasksAgentic AI
Autonomous agents, time horizon, HCAST
5 tasksTrending Models
December 2025 releases analyzed
MiniMax M2.1: 74% SWE-bench at 90% Lower Cost
229B MoE model beats Claude Sonnet 4.5 at $0.30/1M tokens
GLM-4.7: 95.7% AIME 2025
Zhipu AI's 358B model sets math reasoning records
TRELLIS.2: 3D Assets in 3 Seconds
Microsoft's 4B model generates game-ready PBR assets
Hunyuan MT Beats Google Translate
Tencent's 1.8B model wins WMT2025, runs on phones
The Zen of AI Composition
Building intelligent systems from first principles. A philosophical guide to AI transformations, modular composition, and evidence-based prompting.
CodeSOTA
The Zen of AI Composition
Kacper Wikiel
AI Building Blocks
Stop searching. Start building. See which tools transform your data - with production-ready implementations.
Interactive Explainers
3Blue1Brown-style explanations of paradoxes and counterintuitive results. Play with simulations, not just read about them.
In-Depth Comparisons
All guides
SWE-bench SOTA
Which AI agents solve real GitHub issues? Latest scores on SWE-bench Verified.

Mathematical Reasoning
MATH, GSM8K, GPQA benchmarks. How models tackle competition-level problems.
Speech Recognition
LibriSpeech WER scores. Whisper, Conformer, and multilingual ASR compared.
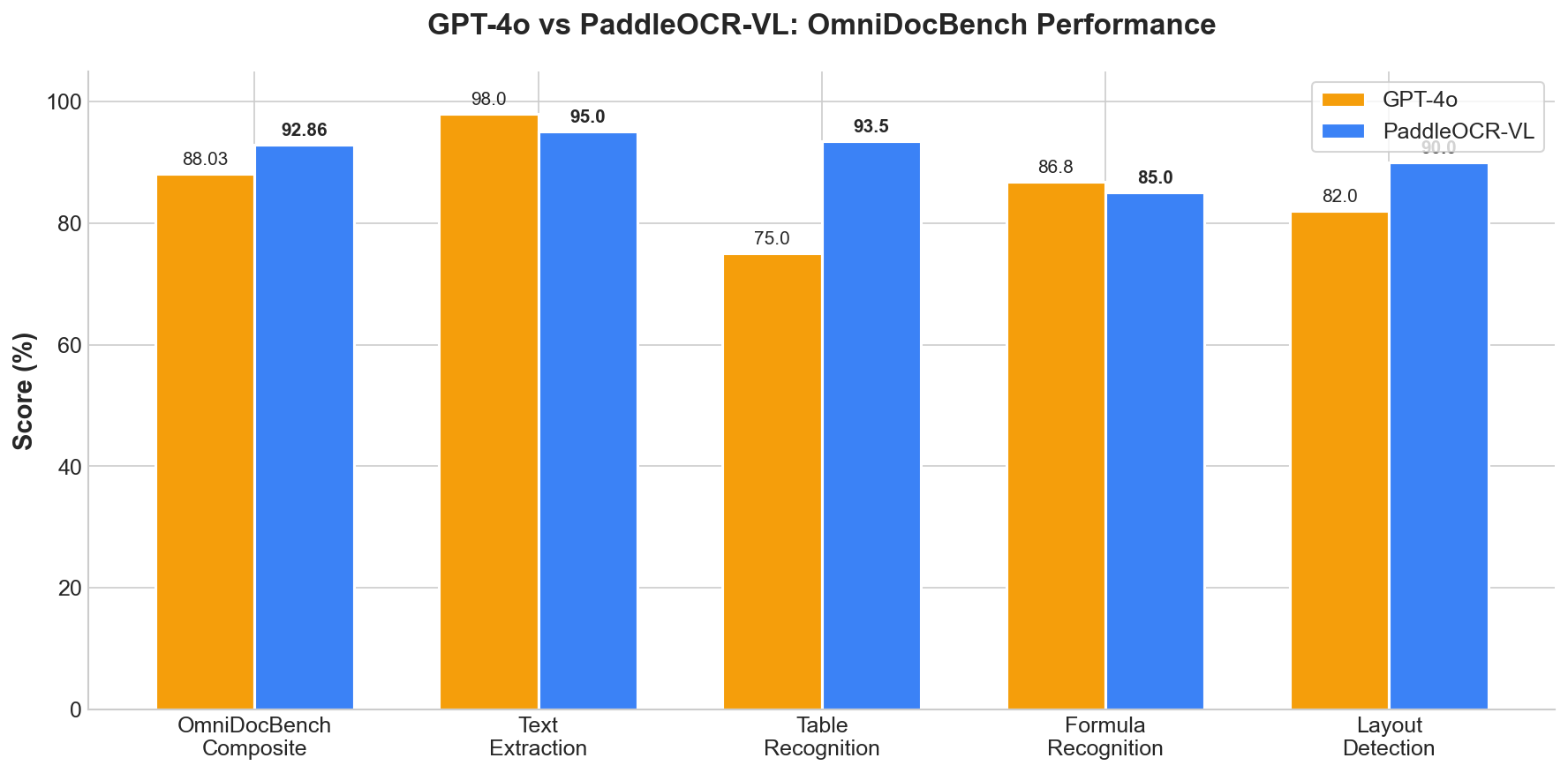
Document OCR
OmniDocBench, OCRBench results. 50+ models tested on real documents.
Chest X-ray AI
CheXpert, MIMIC-CXR benchmarks. AUROC scores for radiology models.

AI Building Blocks
Input-to-output transformations. Find the right architecture for your task.
Can I trust these numbers?
Numbers from published papers, verified with our own tests where possible. No marketing claims, no sponsored rankings.
Which model fits my use case?
Compare accuracy, speed, cost, and deployment complexity. We show you the tradeoffs that matter for production.
Can I use this data?
Yes. All benchmark data available as JSON. Build dashboards, cite it in papers, integrate it into your tools.
Use This Data
All benchmark data available as JSON
Build dashboards, cite in papers, integrate into your tools. No API key needed. Updated weekly with new results.
Frequently Asked Questions
What is CodeSOTA?
CodeSOTA is an independent ML benchmark tracking platform. We provide verified state-of-the-art results across 17 research areas including computer vision, NLP, reasoning, code generation, speech, medical AI, robotics, and more.
Is this a Papers with Code replacement?
CodeSOTA builds on the Papers with Code legacy after Meta shut it down in July 2025. We track 286+ benchmark results with links to implementations. Read the full story.
Are these benchmarks verified?
Yes. We run benchmarks independently where possible, rather than just aggregating paper claims. All data includes source URLs and access dates for verification. See our methodology.
Can I use this benchmark data?
Yes. All benchmark data is available as JSON at /data/benchmarks.json. Build dashboards, cite it in papers, or integrate it into your tools.
What People Say
Anonymous
AI Consultant, Voice-AI at scale
"Outstanding work. Just yesterday I was searching for good OCR comparisons and found only marketing BS. Good job!"
December 2025
Anonymous
Senior Architect
"Super clean, slop-free UI, but most importantly the copy: very precise positioning and project overview."
December 2025
Cite CodeSOTA
If you use CodeSOTA in your research, please cite:
@misc{wikiel2025codesota,
author = {Wikieł, Kacper},
title = {CodeSOTA: Independent ML Benchmark Tracking},
year = {2025},
url = {https://codesota.com},
note = {Accessed: 2025}
}Or in plain text: Wikieł, K. (2025). CodeSOTA: Independent ML Benchmark Tracking. https://codesota.com
Want updates on new benchmarks?
We'll let you know when we add tests for new models or tasks.
No spam. Unsubscribe anytime.